
Emergency project recovery
When production breaks, we help you stabilize fast: identify the cause, restore critical flows, and reduce the risk of the same incident happening again.
CLIENT’S PAIN POINTS
When every minute counts
A production incident is not just a bug. It affects revenue, operations, and trust. These are the most common symptoms teams face.

Sales stall, users churn
Checkout fails, forms stop sending, or key pages crash. Every minute increases lost conversions and puts more pressure on your team.

Release broke prod, rollback is not enough
Migrations misfire, dependencies conflict, or a feature cannot be safely disabled. The deadline is already burning while the team is still diagnosing.

Infrastructure becomes unpredictable
Servers choke under load, queues freeze, redirects behave inconsistently, or SSL/domain issues appear at the worst moment. The risk of repeat incidents stays high.

No visibility into what broke
Logs are incomplete, alerts are missing, and metrics do not explain the failure. Guesswork wastes time while the business impact is already happening.
Start with a practical plan
We review the incident context and suggest the safest next step: what to stabilize first, how to restore service, and what to fix next to reduce repeat risk.
OUR SOLUTION
How we restore control
We follow a crisis recovery protocol: fast context, isolate the cause, restore service safely, and close repeat risks.
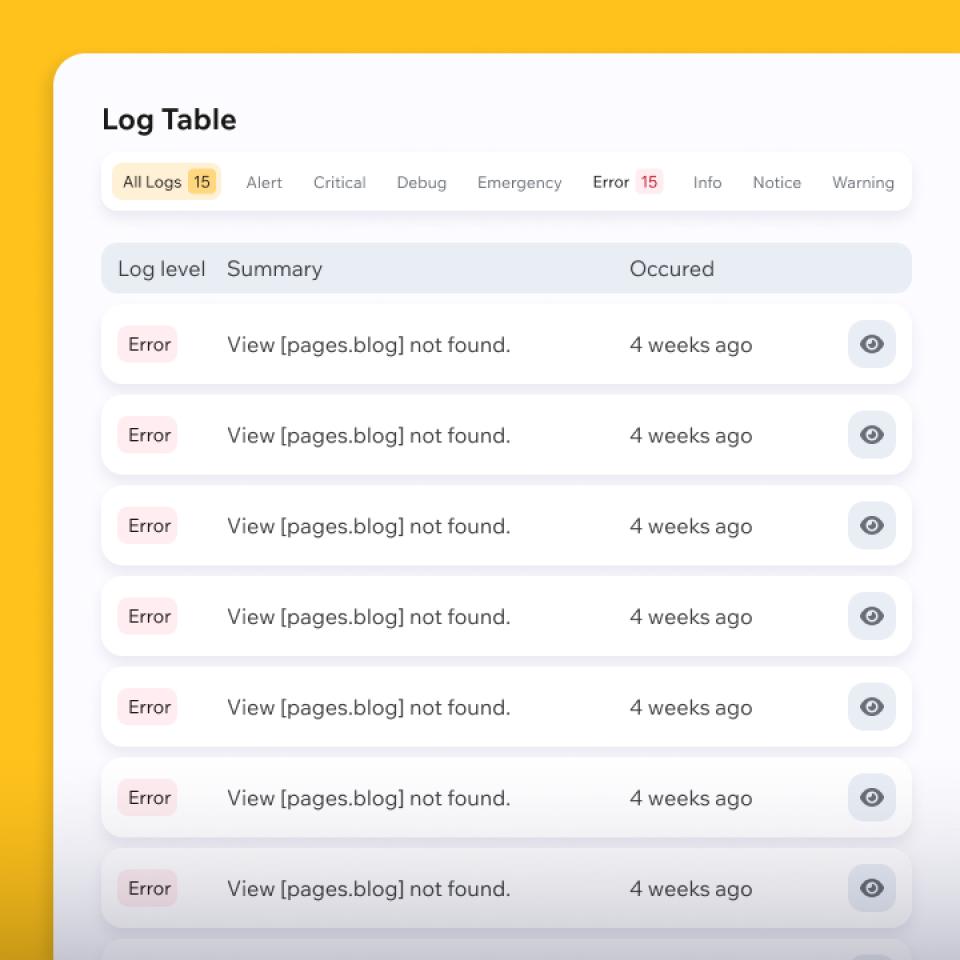
Rapid triage and root-cause isolation
We collect symptoms and access, freeze risky changes, and analyze logs, metrics, traces, and recent diffs.
The goal is a confirmed cause with high-signal checks — not guesswork.
You get a clear answer: what broke, why it broke, and what happens next.
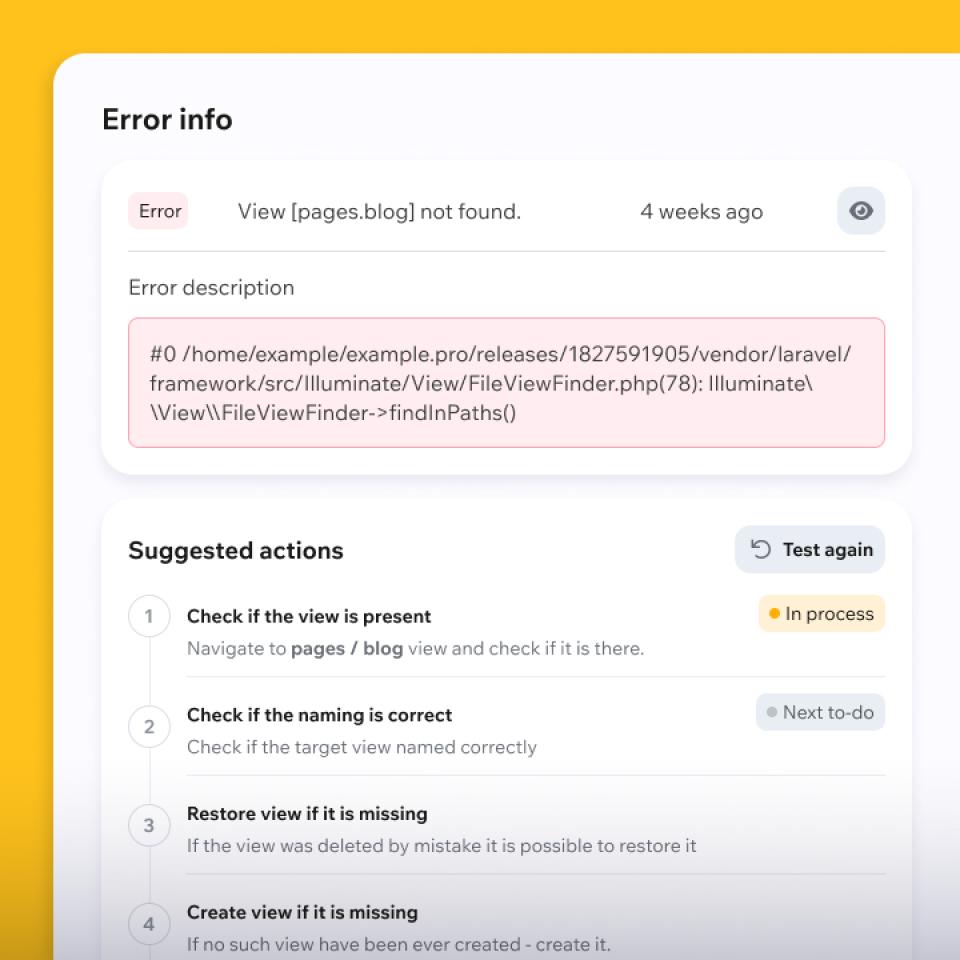
Restore service fast
We choose the safest recovery path: rollback, kill-switch/feature flag, temporary bypass, or a focused hotfix. We validate critical user flows first (checkout, auth, and core operations).
Priority is always to reduce business impact before broader cleanup.
Stabilize and prevent recurrence
We normalize infra/runtime behavior, add monitoring and alerts, and introduce regression guards. You get a concise post-mortem and a prioritized action plan (P0→P2).
HOW IT WORKS?
From request to stability
Fast, transparent, and safe — clear priorities from the first message to service restoration.
Kickoff
Symptoms and business impact
You describe what is broken and what it affects (revenue, traffic, operations). We ask the critical questions, align on P0 priorities, and focus first on what blocks users and money.
Access
Minimal access, maximum speed
We request only what is necessary: repo, hosting/server, logs/Sentry, database, CDN, and related services. We freeze deployments and secure a backup/snapshot so changes stay reversible.
Restore
Triage, recover, hotfix
We isolate the cause with logs, metrics, and diffs, then choose the safest recovery path — rollback, kill-switch, bypass, or targeted hotfix. Critical flows are validated before we move on.
Stabilize
Prevent the next incident
We improve monitoring, alerts, and safeguards, and fix repeat-risk issues in queues, cache, DB, or config. You receive a short incident report plus a prioritized next-step plan.
And this is where recovery starts
How much it costs?
Transparent crisis Pricing
Two support options depending on urgency: immediate incident response or rapid crisis assessment. Scope and pricing are confirmed after the initial review.
Included
- Priority onboarding after required access is provided
- Live incident triage and impact assessment
- Root cause investigation (code, logs, infra, integrations)
- Safe recovery actions (rollback / hotfix / mitigation)
- Validation of critical user flows after recovery
- Short incident summary with recommended next steps
Example
Production checkout is failing after a deployment, or leads/forms stopped submitting. Once access, logs, and context are provided, I can join within a few hours for live triage, isolate the likely root cause, and implement the safest recovery path (rollback, hotfix, or temporary mitigation) to restore critical functionality.
Included
- Structured technical review of the incident/problem
- Access and evidence review (logs, errors, reports, recent changes)
- Severity and risk assessment
- Recovery options with priorities (P0 / P1 / P2)
- Clear action plan for your team or implementation by me
- Estimate for follow-up recovery/stabilization work (optional)
Example
The system is unstable, errors appear intermittently, or performance dropped after recent changes — but the business is still operating. This package is for a fast expert assessment, identifying the most likely causes and delivering a prioritized recovery plan before the issue escalates into a full production incident.
Active incident or urgent production issue? Let’s assess it quickly and choose the safest recovery path.
FAQ
Common questions
Short answers about emergency recovery engagements.
How quickly can you engage?
Usually the same day once minimal access is available and the response window is confirmed. If the incident is active, we start triage immediately from your request.
How do you price emergency work?
Emergency work is typically billed hourly with a minimum block or as a fixed crisis sprint. We agree on scope boundaries and a hard cap before starting.
Can you stay on after the incident?
Yes, on request. We can continue with stabilization, monitoring/alerts, cleanup, and support during critical release windows.
Do you only work with specific stacks?
We are pragmatic. Our strongest area is modern PHP and common web stacks, but we will tell you early if your case is outside scope.
Can we use an NDA and limit access?
Yes. We can work under your NDA and follow least-privilege access for the duration of the engagement.
What if the cause is unclear?
That is common. We start with fast triage and the safest recovery path to reduce impact first, then confirm the root cause and implement the durable fix.
Will we get a report and a follow-up plan?
Yes. You get a concise post-mortem (what happened, what we changed, why it worked) and a prioritized action plan (P0→P2).
What access do you need?
Usually: repository access, logs/Sentry, hosting/server access, database access, and CDN/Cloudflare. If the incident touches payments, email, or third-party APIs, we may need limited access there too.
How safe are the changes during an emergency?
We work with backups/snapshots, deploy freeze, and reversible changes whenever possible. We prioritize restoring service safely, then add a guard test or monitoring to reduce repeat risk.
What is P0 vs P1 vs P2?
P0 is a critical incident with immediate business damage and requires action now.
P1 is high severity with a workaround or degraded service.
P2 is non-blocking improvement work (stability, monitoring, optimizations) that goes into the follow-up plan after P0/P1 are handled.
GET IN TOUCH
Tell us what is broken
Whether you need urgent production recovery, help stabilizing a recent release, or support diagnosing a recurring outage, we will suggest the best next step.