
Noodherstel van projecten
Als de productie stilvalt, helpen we je om snel weer op gang te komen: we zoeken uit wat er aan de hand is, herstellen belangrijke processen en zorgen ervoor dat hetzelfde niet snel weer gebeurt.
De pijnpunten van de klant
Als elke minuut telt
Een productieprobleem is niet zomaar een bug. Het heeft invloed op de omzet, de bedrijfsvoering en het vertrouwen. Dit zijn de meest voorkomende symptomen waarmee teams te maken krijgen.

Verkoop stagneert, gebruikers haken af
Het afrekenen gaat mis, formulieren worden niet meer verstuurd of belangrijke pagina's crashen. Elke minuut die voorbijgaat, zorgt voor meer gemiste conversies en meer druk op je team.

Release is mislukt, terugdraaien is niet genoeg
Migraties mislukken, afhankelijkheden botsen of een functie kan niet veilig worden uitgeschakeld. De deadline nadert al, terwijl het team nog bezig is met het stellen van een diagnose.

De infrastructuur wordt onvoorspelbaar.
Servers raken overbelast, wachtrijen lopen vast, omleidingen werken niet goed of er zijn problemen met SSL/domeinen op het slechtst mogelijke moment. Het risico dat dit weer gebeurt, blijft groot.

Geen idee wat er kapot is gegaan
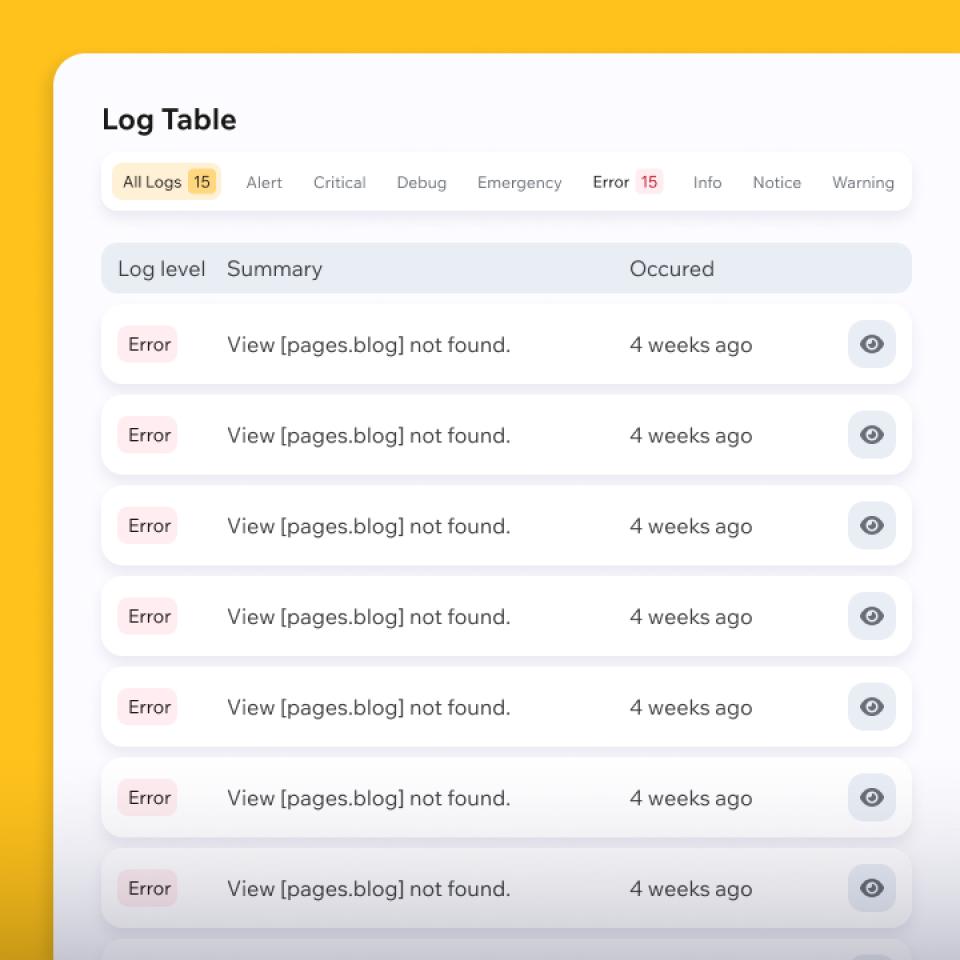
Logs zijn niet compleet, er zijn waarschuwingen niet en de statistieken leggen de storing niet uit. Gissen kost tijd, terwijl het bedrijf er al last van heeft.
Begin met een praktisch plan
We kijken naar wat er precies gebeurd is en geven advies over wat je het beste kunt doen: wat je eerst moet stabiliseren, hoe je de dienst weer op gang kunt brengen en wat je daarna moet aanpakken om te voorkomen dat het weer gebeurt.
ONZE OPLOSSING
Hoe we de controle terugkrijgen
We volgen een protocol voor crisisherstel: snel de situatie begrijpen, de oorzaak vinden, de dienst veilig weer opstarten en herhalingsrisico's voorkomen.
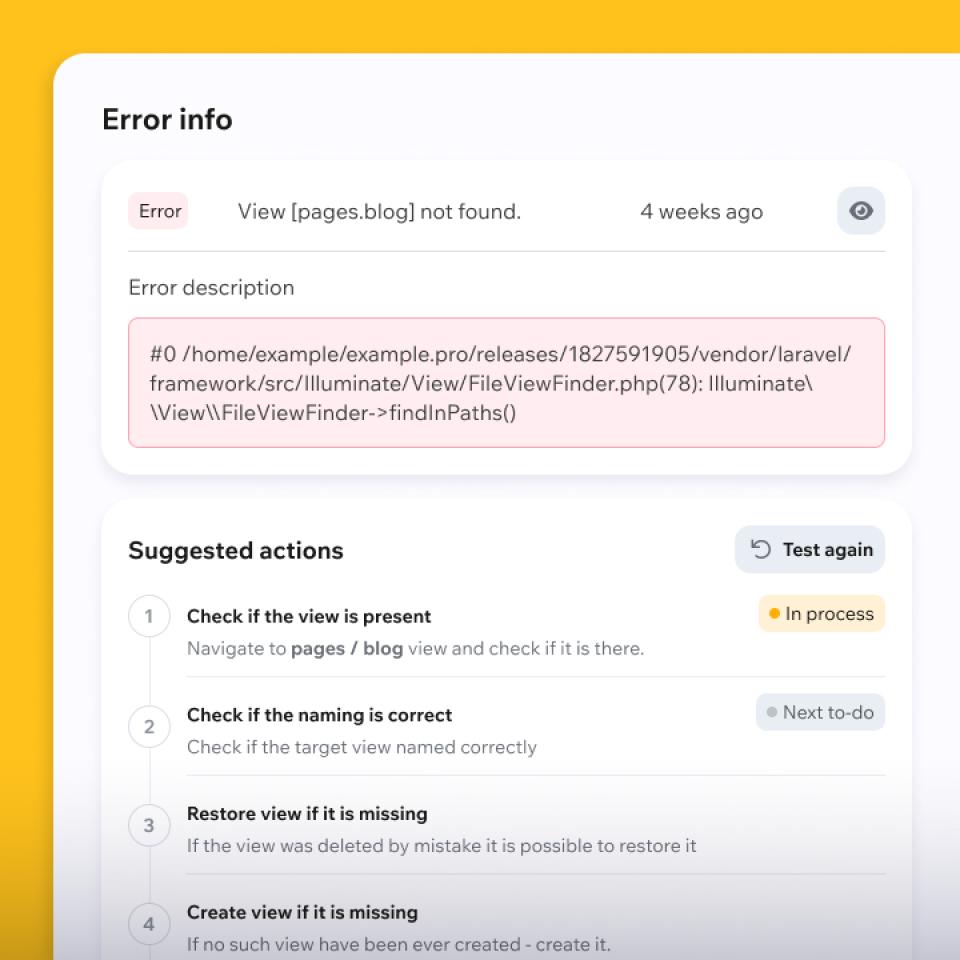
Snelle triage en het achterhalen van de oorzaak
We verzamelen symptomen en toegang, bevriezen risicovolle veranderingen en analyseren logboeken, statistieken, traces en recente verschillen.
Het doel is om de oorzaak te achterhalen met betrouwbare controles, geen giswerk.
Je krijgt een duidelijk antwoord: wat is er kapot, waarom is het kapot en wat gebeurt er nu?
Herstel de service snel
We kiezen de veiligste manier om dingen weer op orde te krijgen: terugdraaien, kill-switch/feature flag, tijdelijke bypass of een gerichte hotfix. We checken eerst de belangrijke gebruikersstromen (afrekenen, authenticatie en kernactiviteiten).
Het belangrijkste is altijd om de impact op het bedrijf te verminderen voordat we verder opruimen.
Stabiliseren en herhaling voorkomen
We normaliseren het infra/runtime-gedrag, voegen monitoring en waarschuwingen toe en bouwen regressiebeveiliging in. Je ontvangt een beknopte post-mortem en een geprioriteerd actieplan (P0→P2).
Hoe werkt het?
Van vraag naar stabiliteit
Snel, duidelijk en veilig — dat zijn de belangrijkste dingen, van het eerste bericht tot het weer werken van de dienst.
Start
Symptomen en impact op het bedrijf
Je vertelt wat er niet goed werkt en wat de gevolgen zijn (omzet, verkeer, activiteiten). We stellen de belangrijke vragen, spreken P0-prioriteiten af en richten ons eerst op wat gebruikers en geld in de weg staat.
Toegang
Minimale toegang, maximale snelheid
We vragen alleen wat echt nodig is: repo, hosting/server, logs/Sentry, database, CDN en aanverwante diensten. We zetten implementaties even stil en zorgen voor een back-up/snapshot, zodat wijzigingen altijd teruggedraaid kunnen worden.
Herstellen
Triage, herstellen, hotfix
We zoeken de oorzaak met logs, statistieken en diffs, en kiezen dan de veiligste manier om het op te lossen: terugdraaien, kill-switch, omzeilen of een gerichte hotfix. Belangrijke processen worden gecontroleerd voordat we verder gaan.
Stabiliseren
Voorkom het volgende incident
We verbeteren monitoring, waarschuwingen en beveiligingen, en lossen terugkerende risico's op in wachtrijen, cache, databases of configuraties. Je krijgt een kort incidentrapport en een plan met prioriteiten voor de volgende stappen.
En hier begint het herstel
Hoeveel kost het?
Transparante crisis Prijzen
Twee ondersteuningsopties, afhankelijk van hoe dringend het is: direct reageren op een incident of snel een crisisbeoordeling doen. Wat er precies gebeurt en wat het kost, wordt na de eerste beoordeling duidelijk.
Inbegrepen
- Je krijgt voorrang bij het onboarden nadat je de benodigde toegang hebt gekregen.
- Live triage van incidenten en beoordeling van de gevolgen
- Onderzoek naar de oorzaak (code, logboeken, infrastructuur, integraties)
- Veilige herstelacties (rollback / hotfix / mitigatie)
- Controle van belangrijke gebruikersstromen na herstel
- Korte samenvatting van het incident met wat je nu het beste kunt doen
Voorbeeld
De productiecontrole loopt niet lekker na een implementatie, of leads/formulieren worden niet meer verstuurd. Zodra ik toegang, logboeken en context krijg, kan ik binnen een paar uur meedoen voor live triage, de waarschijnlijke oorzaak vinden en de veiligste manier van herstel (rollback, hotfix of tijdelijke oplossing) doen om belangrijke functies weer te laten werken.
Inbegrepen
- Een gedetailleerde technische analyse van het probleem of incident
- Toegang en bewijs bekijken (logboeken, fouten, rapporten, recente wijzigingen)
- Ernst en risicobeoordeling
- Herstelopties met prioriteiten (P0 / P1 / P2)
- Een duidelijk actieplan voor je team of ik zorg ervoor dat het gebeurt
- Schatting voor vervolgwerkzaamheden voor herstel/stabilisatie (optioneel)
Voorbeeld
Het systeem is een beetje onstabiel, er zijn af en toe fouten of de prestaties zijn minder sinds die recente veranderingen, maar het bedrijf draait nog steeds. Dit pakket is voor een snelle beoordeling door experts, die kijken wat de meest waarschijnlijke oorzaken zijn en een herstelplan met prioriteiten maken voordat het probleem uitgroeit tot een groot productie-incident.
Heb je een probleem of een dringende productie-uitdaging? Laten we het snel bekijken en de veiligste manier kiezen om het op te lossen.
Veelgestelde vragen
Veelgestelde vragen
Korte antwoorden over noodherstelopdrachten.
Hoe snel kun je meedoen?
Meestal dezelfde dag als er een beetje toegang is en het reactietijdvenster is bevestigd. Als het incident nog bezig is, beginnen we meteen met triage vanaf je verzoek.
Hoe bepaal je de prijs voor spoedwerk?
Noodwerk wordt meestal per uur gefactureerd met een minimumtarief of als een vaste crisissprint. We spreken vooraf de omvang en een maximumtarief af.
Kun je na het incident blijven?
Ja, als je dat wilt. We kunnen doorgaan met stabilisatie, monitoring/waarschuwingen, opschoning en ondersteuning tijdens belangrijke release-periodes.
Werk je alleen met bepaalde stacks?
We zijn praktisch ingesteld. Onze sterkste kant is moderne PHP en gangbare web stacks, maar we laten je meteen weten als je vraag buiten ons bereik valt.
Kunnen we een geheimhoudingsverklaring gebruiken en de toegang beperken?
Ja. We kunnen onder jouw geheimhoudingsverklaring werken en zorgen dat we alleen toegang krijgen tot wat we echt nodig hebben tijdens onze samenwerking.
Wat als de oorzaak niet duidelijk is?
Dat is normaal. We beginnen met een snelle triage en het veiligste herstelpad om eerst de impact te verminderen, daarna kijken we naar de oorzaak en zorgen we voor een blijvende oplossing.
Krijgen we een rapport en een plan voor de toekomst?
Ja. Je krijgt een korte analyse achteraf (wat is er gebeurd, wat hebben we veranderd, waarom werkte het) en een actieplan met prioriteiten (P0→P2).
Welke toegang heb je nodig?
Meestal: toegang tot de repository, logs/Sentry, hosting/servertoegang, databasetoegang en CDN/Cloudflare. Als het incident te maken heeft met betalingen, e-mail of API's van derden, hebben we daar misschien ook beperkte toegang nodig.
Hoe veilig zijn de veranderingen tijdens een noodgeval?
We werken met back-ups/snapshots, implementeren bevriezing en omkeerbare wijzigingen waar mogelijk. We geven prioriteit aan het veilig herstellen van de service en voegen vervolgens een beveiligingstest of monitoring toe om herhalingsrisico's te verminderen.
Wat is het verschil tussen P0, P1 en P2?
P0 is een ernstig incident dat meteen schade aan het bedrijf veroorzaakt en waar je meteen iets aan moet doen.
P1 is een ernstig incident waarvoor een tijdelijke oplossing of een minder goede service nodig is.
P2 is niet-blokkerend verbeteringswerk (stabiliteit, monitoring, optimalisaties) dat in het vervolgplan komt nadat P0/P1 zijn afgehandeld.
Neem contact op
Vertel ons wat er kapot is
Of je nu snel je productie weer op gang moet krijgen, hulp nodig hebt om een recente release stabiel te houden of ondersteuning nodig hebt bij het oplossen van een terugkerende storing, wij helpen je met de beste volgende stap.