Développeur de crise : comment se stabiliser rapidement et éviter les répétitions

Les incidents de production nuisent au chiffre d'affaires et à la confiance. Un développeur de crise est une intervention pratique à court terme : contenir l'impact, trouver et réparer la cause première, renforcer le système et remettre un plan clair pour que cela ne se reproduise plus. Les exemples peuvent faire référence à PHP/Laravel, mais l'approche est indépendante de la pile.
Ce qu'est ce rôle - et pourquoi il existe
Un développeur de crise intervient lorsque la cadence de livraison habituelle ne suffit plus : les incidents atteignent P0/P11, la conversion chute, les files d'attente stagnent ou les intégrations déstabilisent les flux de base. L'objectif n'est pas de faire preuve d'héroïsme ou de tout réécrire, mais de gérer la reprise: stabiliser, trouver la cause première, combler les lacunes systémiques et restituer les connaissances à l'équipe.
Notre méthode de travail : trois étapes étroitement délimitées
1) Stabilisation - confinement et rétablissement du service
- Rétablir ou mettre sous drapeau les parties à risque ; désactiver temporairement les fonctions non critiques qui amplifient le rayon de l'explosion.
- Activez la télémétrie ; capturez les artefacts (journaux, traces, dumps, migrations récentes de la base de données).
- Objectif : les chemins critiques pour l'entreprise (inscription, recherche, panier, paiement) fonctionnent à nouveau de manière prévisible.
2) Réparation - éliminer la cause première, et pas seulement les symptômes
- RCA : conditions de course dans les files d'attente, idempotence manquante dans les rappels de paiement, requêtes de base de données non indexées, délais d'attente mal configurés.
- Remède : modifications du code et de la configuration et politiques (tentatives, délais, limites, verrous, idempotence).
- Les tests de régression permettent d'éviter que le bogue ne revienne par une porte latérale.
3) Prévenir - renforcer et surveiller
- Alertes au niveau de l'entreprise (taux d'erreur de paiement, augmentation des 5xx, dégradation du p95) et responsabilité claire.
- Runbooks pour les incidents courants ; listes de contrôle simples et exploitables.
- Définissez les OLS en termes commerciaux : ce que signifie "fonctionner" et comment cela est mesuré.
À propos des chiffres - prudence et honnêteté
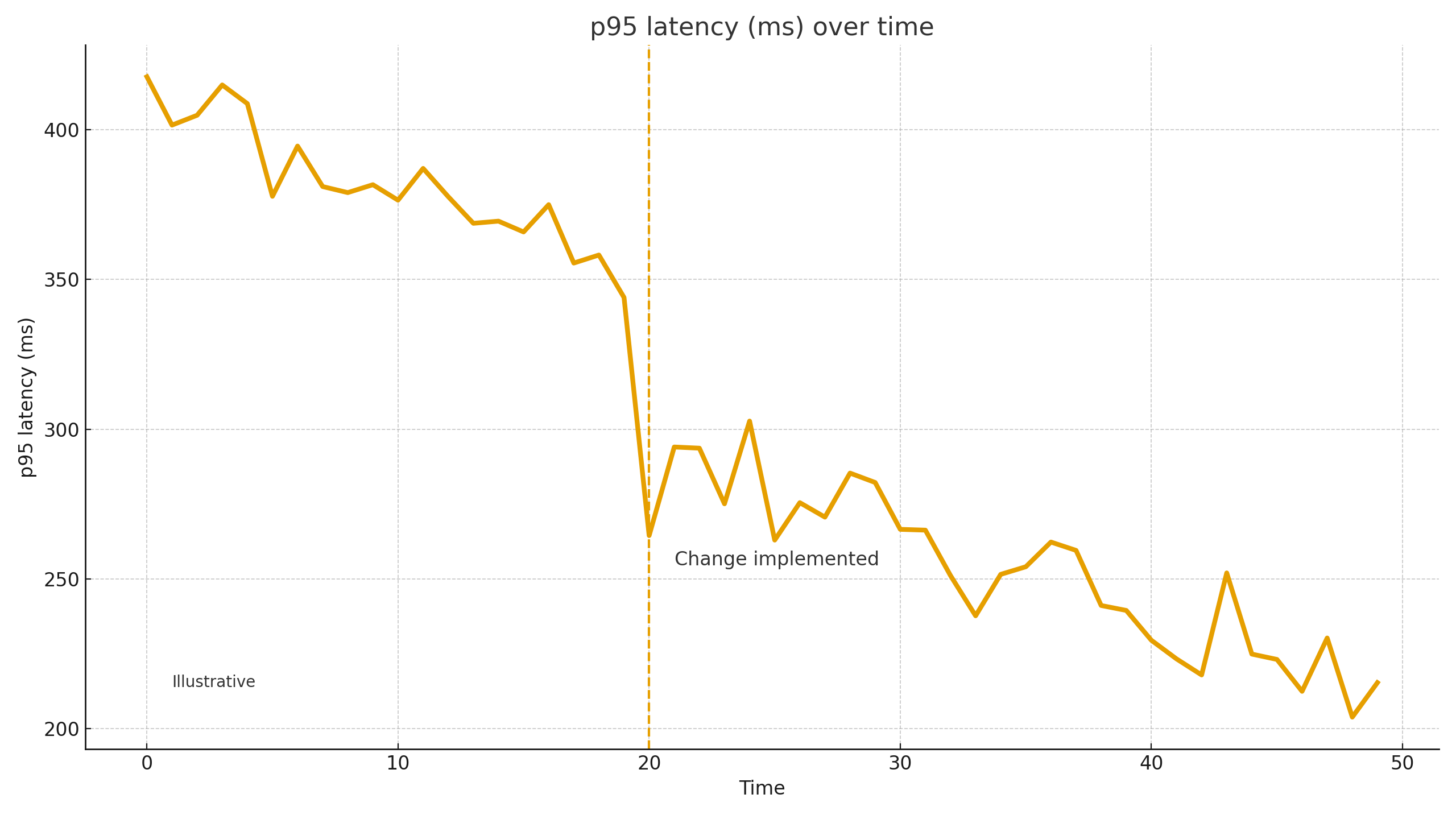
Dans les situations de crise, les chiffres sont des illustrations et non des promesses. Sur des projets similaires, après avoir éliminé un goulot d'étranglement, nous avons vu le p95 d'une API clé chuter de ~30-60%, les erreurs 5xx et de paiement diminuer de ~40-80% grâce à l'idempotency et aux politiques de réessai/timeout, et la conversion des commandes rebondir de +5-20%. Le MTTR est souvent multiplié par plusieurs une fois que des alertes et un manuel d'exécution simple existent. Les résultats finaux dépendent de l'architecture, de la qualité du code, du profil du trafic et de la maturité du processus.
1) P0 / P1. Dans les schémas courants de priorité des incidents, P0 est un blocage total : indisponibilité critique du produit ou d'un flux commercial clé (par exemple, défaillance généralisée des paiements). P1 est une priorité très élevée : une dégradation fonctionnelle majeure ayant un impact sur de nombreux utilisateurs ou de l'argent, mais pas une panne totale.
2) p95 (95e percentile du temps de réponse). Il s'agit d'une mesure de performance : la valeur en dessous de laquelle 95 % des demandes aboutissent. Si le p95 de la caisse de sortie = 2,4 secondes, 95 % des utilisateurs franchissent cette étape en moins de 2,4 secondes, tandis que les 5 % les plus lents prennent plus de temps. La gestion du p95 cible la "queue douloureuse" qui nuit à l'expérience utilisateur et à la conversion.
Contactez-nous
Besoin d’un
développeur de crise
Nous intervenons sur pannes, déploiements échoués et bugs P0 (blocants)—triage, hotfix sécurisé ou rollback, avec prochaines étapes claires.