Crisisontwikkelaar: hoe je snel stabiliseert en herhaling voorkomt

Productie-incidenten schaden de omzet en het vertrouwen. Een crisisontwikkelaar is een hands-on interventie op korte termijn: de impact beperken, de hoofdoorzaak vinden en verhelpen, het systeem verharden en een duidelijk plan overhandigen zodat het niet nog eens gebeurt. Voorbeelden kunnen verwijzen naar PHP/Laravel, maar de aanpak is stack-agnostisch.
Wat deze rol is - en waarom hij bestaat
Een crisisontwikkelaar treedt in dienst wanneer de gebruikelijke opleveringscadans niet langer helpt: incidenten bereiken P0/P11, conversie daalt, wachtrijen lopen vast of integraties destabiliseren de kernstromen. Het doel is niet heldendom of alles herschrijven, maar beheerd herstel: stabiliseren, de hoofdoorzaak vinden, systeemhiaten dichten en kennis teruggeven aan het team.
Hoe we werken: drie nauw omschreven fasen
1) Stabiliseren - insluiting & serviceherstel
- Rollback of feature-flag risicovolle onderdelen; schakel tijdelijk niet-kritische functies uit die de ontploffingsradius vergroten.
- Schakel telemetrie in; leg artefacten vast (logs, traces, dumps, recente DB-migraties).
- Doel: bedrijfskritische paden (aanmelden, zoeken, winkelwagentje, afrekenen) werken weer voorspelbaar.
2) Oplossen - de hoofdoorzaak verwijderen, niet alleen de symptomen
- RCA: race condities in wachtrijen, ontbrekende idempotency in betaal callbacks, niet geïndexeerde DB queries, verkeerd geconfigureerde timeouts.
- Remedie: code & configuratie wijzigen plus beleid (retries, timeouts, limieten, sloten, idempotency).
- Regressietesten beschermen tegen het terugkeren van de bug via een zijdeur.
3) Voorkomen - verharden en bewaken
- Waarschuwingen op bedrijfsniveau (betalingsfoutenpercentage, piek in 5xx, achteruitgang van p95) en duidelijk eigenaarschap.
- Runbooks voor veelvoorkomende incidenten; eenvoudige, uitvoerbare checklists.
- SLO's definiëren in zakelijke termen: wat "werken" betekent en hoe het wordt gemeten.
Over de cijfers - voorzichtig en eerlijk
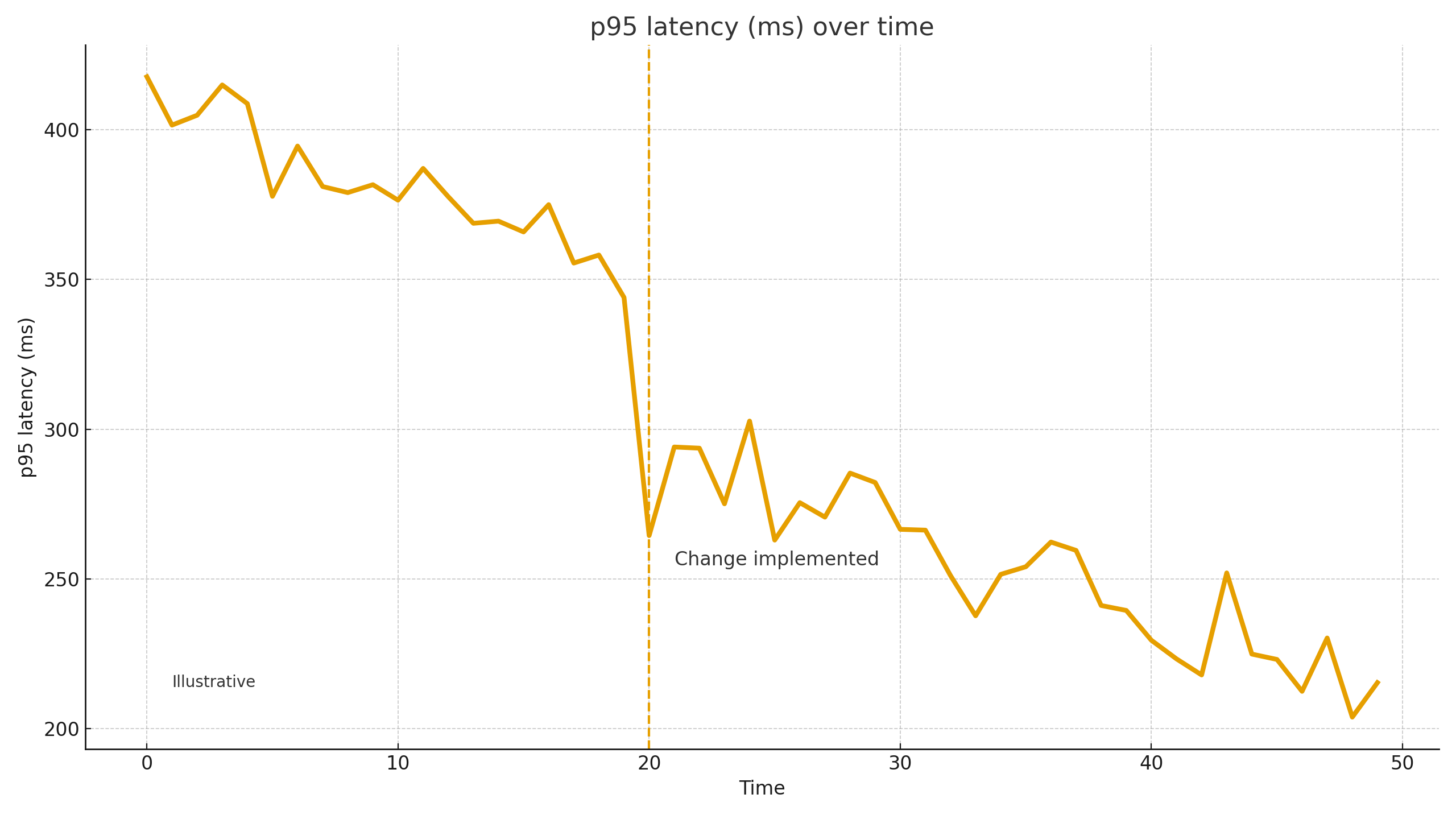
Cijfers in crisiswerk zijn illustratief, geen beloftes. Bij vergelijkbare projecten hebben we, na het verwijderen van een knelpunt, de p95 van een belangrijke API zien dalen met ~30-60%, 5xx en betalingsfouten met ~40-80% dankzij idempotency en retry/timeout beleid, en de conversie bij het afrekenen met +5-20%. MTTR daalt vaak met een veelvoud als er eenmaal waarschuwingen en een eenvoudig runbook zijn. De uiteindelijke resultaten zijn afhankelijk van de architectuur, de kwaliteit van de code, het verkeersprofiel en de volwassenheid van het proces.
1) P0 / P1. In gangbare incidentprioriteitenprogramma's is P0 een volledige blokkering: kritieke onbeschikbaarheid van het product of een belangrijke bedrijfsstroom (bijv. betalingen die op grote schaal mislukken). P1 heeft een zeer hoge prioriteit: een grote functionele degradatie die veel gebruikers of geld beïnvloedt, maar geen totale uitval.
2) p95 (95e percentiel van responstijd). Een prestatiemeting: de waarde waaronder 95% van de verzoeken wordt voltooid. Als afrekenen p95 = 2,4s, dan voltooit 95% van de gebruikers die stap sneller dan 2,4s, terwijl de langzaamste 5% er langer over doet. Het beheren van p95 richt zich op de "pijnlijke staart" die UX en conversie schaadt.
Neem contact op
Productieprobleem?
Crisis-developernodig
We stappen in bij outages, mislukte releases en P0-bugs—triage, veilige hotfix of rollback, plus een duidelijk vervolgstapplan.